
How to Stop Charging Customers Twice: A Practical Idempotency Guide
Idempotency in plain English: HTTP, message queues, and the one detail that decides whether it's real.
Share this post & I’ll send you some rewards for the referrals.
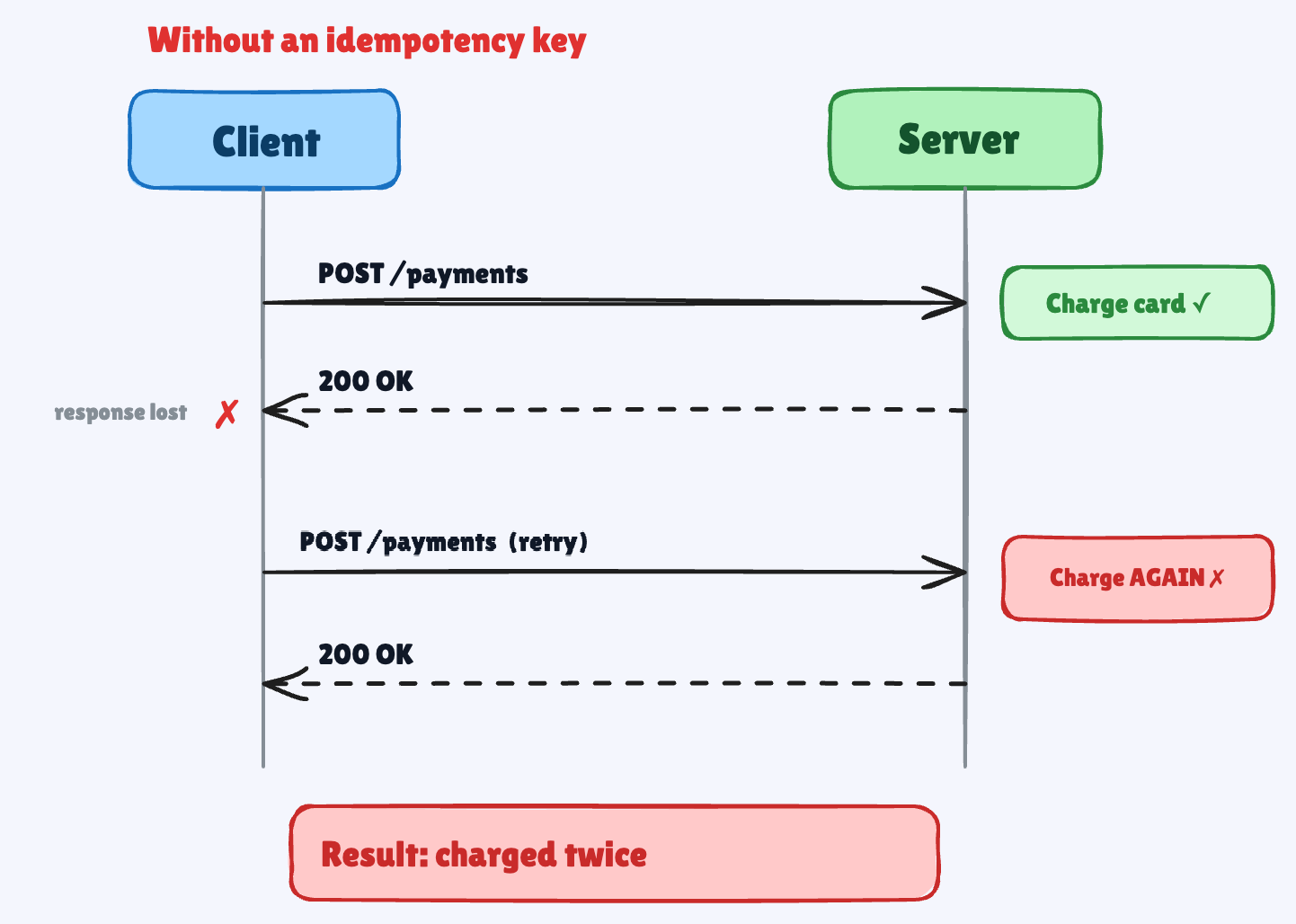
A payment times out. Your user has no idea if it went through, so they hit “Pay” again.
Now you’ve charged them twice, and the angry email is already on its way.
Idempotency is how you stop that. It’s a simple idea with a sharp edge, and most explanations get the idea right and the edge wrong. This one won’t.
The agent harness wasn't supposed to be the black box (Partner)
Agent loop is the most important piece of infrastructure in your workflow right now and for most developers, it’s the one piece they can’t open up. Agent builders have to jump through all the hoops themselves, crafting the infrastructure and tools, testing the harness, while fighting to maintain what they’ve built.

Meet Cline SDK: agent harness behind Cline 2.0, fully open-sourced. The same runtime that powers Cline across VS Code, JetBrains, and the CLI is now an npm install away: npm i @cline/sdk. Inspect it, fork it, extend it, ship on it.
Best-in-class harness: 74.2% on Terminal-Bench 2.0 with Claude Opus 4.7 ahead of Claude Code (69.4%) and strongest numbers published on open-weight models.
Open model & provider choice: Anthropic, OpenAI, Google, Bedrock, Mistral, or any OpenAI-compatible endpoint.
Real plugin system: Register tools, hooks, commands, providers, message builders. Prototype as a local file, harden into a package. Extend it freely for any of your agent use cases.
Scheduled + event-driven agents: Cron and event specs for PR reviews, dependency checks, coverage audits, changelogs no separate orchestration layer.
Stop building around your agent. Start building on it.
Install Cline SDK today: npm i @cline/sdk. Or try the rebuilt harness directly: npm i -g @cline
(Thanks to Cline for partnering on this post.)
What Idempotency Means?
An operation is idempotent if running it ten times leaves the system in the same state as running it once.
Reading your bank balance is idempotent. Check it a hundred times, nothing changes. Transferring $100 is not, each call moves more money.
That’s the whole definition. The real question is what you do about the operations that aren’t idempotent but still need to survive a retry.
Why you can’t Dodge This?
Retries aren’t an edge case. They’re the default behavior of the systems your code already runs on:
Users and browsers re-submit when a request hangs.
Load balancers and gateways retry on a timeout.
Service meshes auto-retry calls between services.
Message brokers redeliver when a consumer is slow to ack.
Every one of these promises at-least-once — a polite way of saying “sometimes twice.” You don’t get to opt out. You only get to decide whether a duplicate is harmless or expensive.
Idempotency in HTTP Methods
HTTP already has opinions here, and they’re worth knowing:
GET, HEAD — safe and idempotent. Read-only, change nothing.
PUT, DELETE — idempotent, not safe.
PUTsets a resource to a final state; do it twice, same result.DELETEtwice leaves the thing just as deleted.POST, PATCH — not idempotent. Each
POSTwants to create something new.
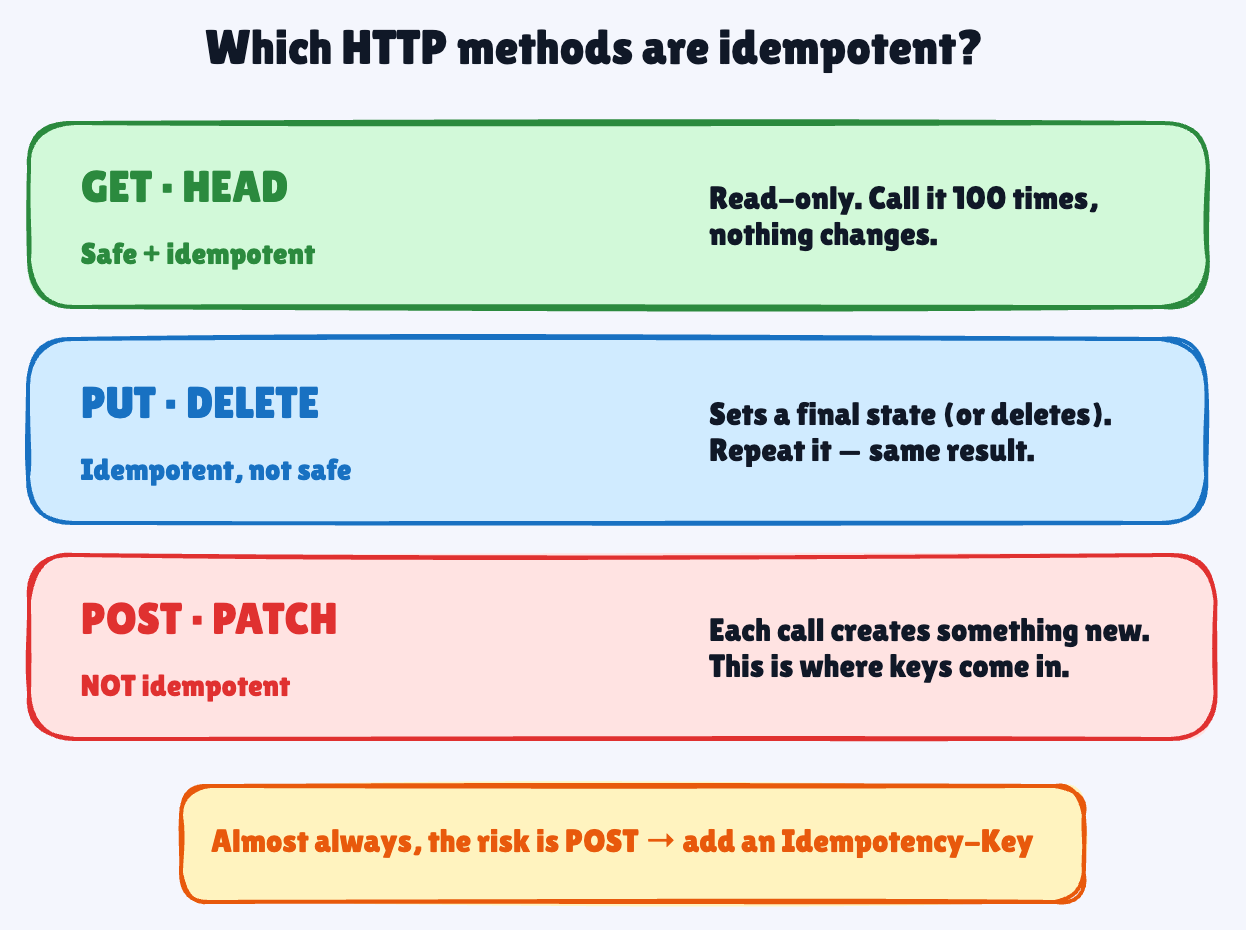
So the trouble is almost always POST. The fix is an idempotency key: the client picks a unique value per operation and sends it as a header.
Idempotency-Key: 9f1c8e2a-7b3d-4f6a-91cd-2e5b7a0c4d11Same operation, same key — even across retries. The server uses it to recognize “I’ve seen this one” and skip the duplicate. It’s exactly what Stripe, Square, and Shopify do.
Idempotency in Messaging Systems
Queues have the same problem, only worse. A broker that guarantees at-least-once delivery will hand your consumer the same message twice — after a redeploy, a slow ack, a partition rebalance.
So the rule I follow is blunt:
Every message consumer must be idempotent.
The shape is always the same — before processing a message, check whether you’ve already handled its ID; if yes, skip; if no, process it and record the ID, in one transaction.
Doing that reliably (and publishing messages you won’t lose) is a bigger topic with its own moving parts — the transactional outbox and idempotent consumer patterns.
Note: I’d cover this in a separate post.
Here, just hold onto the rule:
Aassume every message can arrive twice!
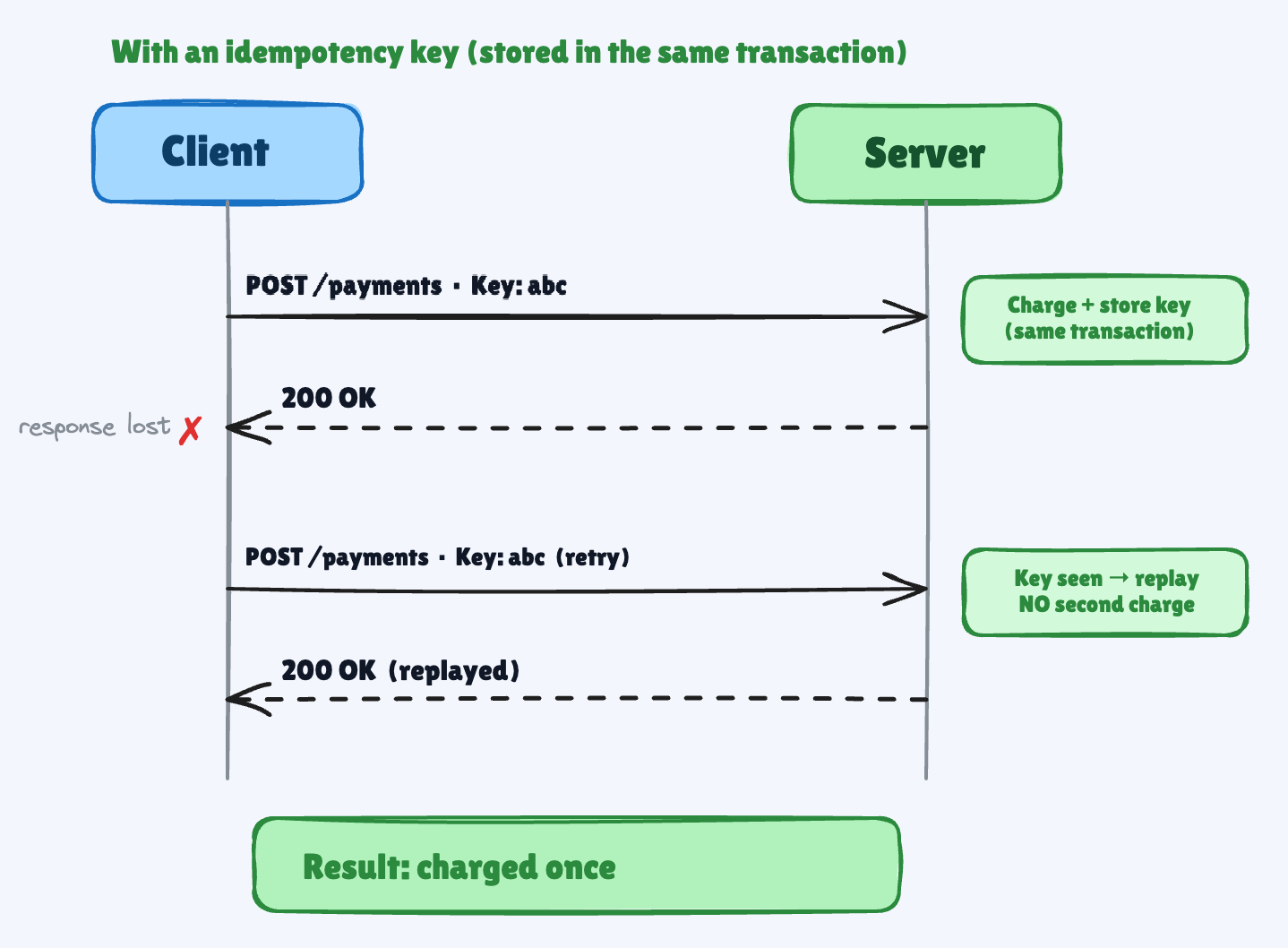
Where you Store the Key is the Whole Game
Now the sharp edge. There are two different jobs hiding under “idempotency,” and people build the easy one while believing they got the hard one:
Replay — return the same response to a duplicate request. Nice for the client.
Exactly-once effect — make sure the card is charged once, no matter what.
A lot of guides stash the response in Redis and replay it. That’s job #1. It does nothing for job #2. If the thing that prevents double-processing lives in a cache, separate from your real data, and you write to it after the work is done — there’s a gap. The charge commits, the process dies before the cache write, the retry charges again.
The guarantee doesn’t come from the key. It comes from where you keep it. Store the key in the same database, in the same transaction, as the work — and let a unique constraint be the thing that says “no, already done”.
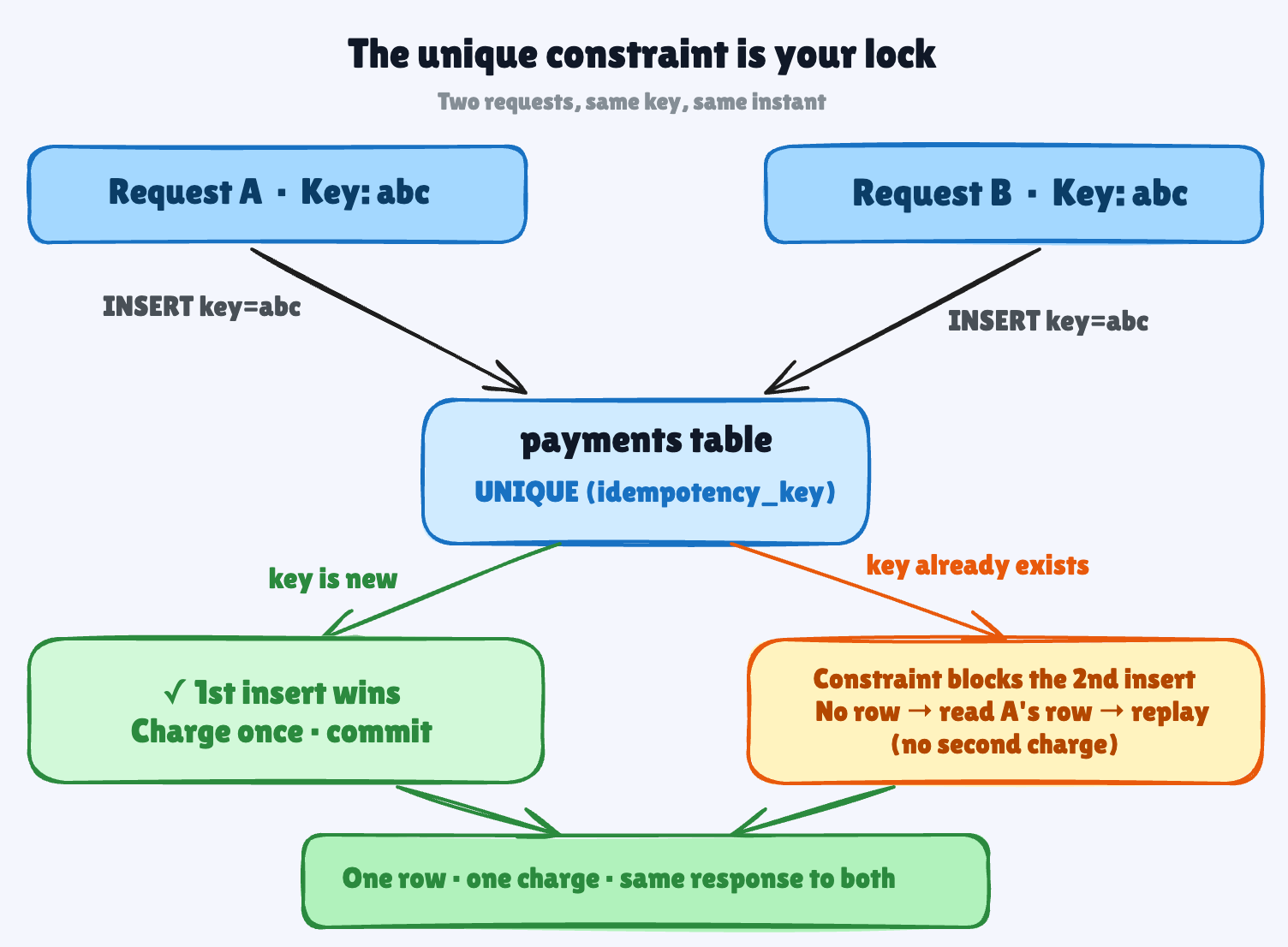
CREATE TABLE payments (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
idempotency_key TEXT UNIQUE NOT NULL, -- this constraint is the whole trick
amount INTEGER NOT NULL,
status TEXT NOT NULL DEFAULT 'pending'
);Two requests with the same key race. Both try to insert. The database lets exactly one win; the loser bounces off the constraint and reads back the winner’s row.
In Postgres you don’t even have to catch an error for that:
INSERT ... ON CONFLICT (idempotency_key) DO NOTHINGThis claims the key when it’s new and quietly steps aside when it isn’t.
No row came back? You’ve seen this key before; go return the stored result.
No hand-rolled lock, no Redis required. Databases were built for precisely this.
And that column doesn't have to be a dedicated idempotency_key.
If the request already carries something unique, like an invoice id, an order number, the message id your broker hands you, put the unique constraint on that, and you need no separate key at all.
A client-generated idempotency key is just the general-purpose version for operations that have no natural identity of their own.
The real mechanism is always the same: a unique identity, backed by a constraint.
Redis still has a place: as a fast cache in front of that constraint, so honest retries get their answer in a millisecond. Just keep the order straight:
Postgres makes you correct, Redis makes you fast.
Flip those, and you’re trusting a cache with money.
Challenges Worth Knowing About
A few things that bite people, so they don’t bite you:
Storage is the guarantee. If your dedup state isn’t durable and transactional, you don’t have idempotency — you have a probability.
Same key, different body. A client reuses a key but changes the payload. Store a hash of the request and reject the mismatch instead of silently replaying the wrong response.
Don’t cache failures. Store the result after the fact and you can accidentally cache a
500, then replay it forever. Tie the record to the transaction so a failure rolls back and the retry runs clean.The expiry window. Keys can’t live forever, so you set a TTL — 24 hours is a common default. A delayed retry that lands after expiry looks brand new again. Match the window to how long retries can realistically arrive.
Some operations a key can’t replay. “Create a payment” has a result to store. “Add $100 to a balance” doesn’t — its outcome depends on current state. Those need a different tool, not a stored response.
Don’t over-engineer. A
PUTor an upsert is already idempotent. Don’t bolt a key table onto an endpoint where duplicates are harmless. The pattern has a cost; spend it where it pays.
Best Practices
Generate the key once per operation, and reuse it on every retry. Regenerate it and you’re back to double charges.
Let the client own the key — it’s the only one that knows which attempts are “the same operation”.
Store keys in durable, transactional storage. Unique constraint first, cache second.
Retry on network errors too, not just bad status codes — a dropped connection is the case you actually care about, and it usually throws instead of returning a status.
Pair idempotency with sane retries — timeouts, backoff, jitter. Retries without those turn a blip into an outage. (Note: I’d cover this in a separate post)
Document which endpoints accept an idempotency key. A guarantee nobody knows about doesn’t get used.
Test the failure path, not just the happy one — especially “a failed attempt doesn’t poison the retry”.
📌 TL;DR
Idempotency = safe to repeat. Run it once or ten times, same end state.
Retries are everywhere — users, load balancers, meshes, brokers. Everything is at-least-once. Assume duplicates.
GET/PUT/DELETE are idempotent by spec; POST isn’t — that’s where idempotency keys come in.
Every message consumer must be idempotent — brokers redeliver.
A header alone doesn’t save you. Replaying a cached response is not the same as guaranteeing the effect happens once.
The guarantee is storage — key and work in the same transaction, behind a unique constraint. Redis is a speed layer, never the source of truth.
Mind the edges — fingerprint mismatches, cached failures, TTL windows, state-dependent ops.
Don’t over-engineer endpoints that are already idempotent.
Thanks for reading, and stay awesome! 🙏

Follow me on LinkedIn | Twitter(X) | Threads
Thank you for supporting this newsletter.
Consider sharing this post with your friends and get rewards.
You are the best! 🙏

Press the Like button if you found this post helpful