
GraphQL Intro 101 (part 2)
A conscious introduction to the GraphQL World, part 2.

Intro
In the first part of GraphQL Intro 101, we covered:
what is GraphQL and some history
why and how GraphQL started
use cases and examples
pros & cons of GraphQL
You can the previous article here: GraphQL Intro 101 (part 1).
In the second part of GraphQL Intro 101, we will dig deeper into the Core Concepts of GraphQL and some high-level architectures in which GraphQL is used.
After reading this article, you’ll learn:
Core Concepts of GraphQL like Queries, Mutations, Schema Definition Language (SDL), GraphQL Schema, Resolvers
3 high-level architectures representing use cases of GraphQL, demonstrating its flexibility
Core Concepts
Queries
Queries are used to read or fetch data. They represent the way clients can request specific data from a GraphQL Server. Unlike REST where multiple endpoints return fixed data structures, a GraphQL query retrieves exactly what the client requests.
Clients define the structure of the data they need, selecting from the types and fields defined in the GraphQL schema. This selective querying helps avoid over-fetching and under-fetching, common issues in REST APIs.

Mutations
Mutations are how we change data in GraphQL like creating new data, updating and deleting existing data.
Similar to queries in syntax, but instead of just fetching data, mutations modify server-side data and typically return the new state of the data after mutation.
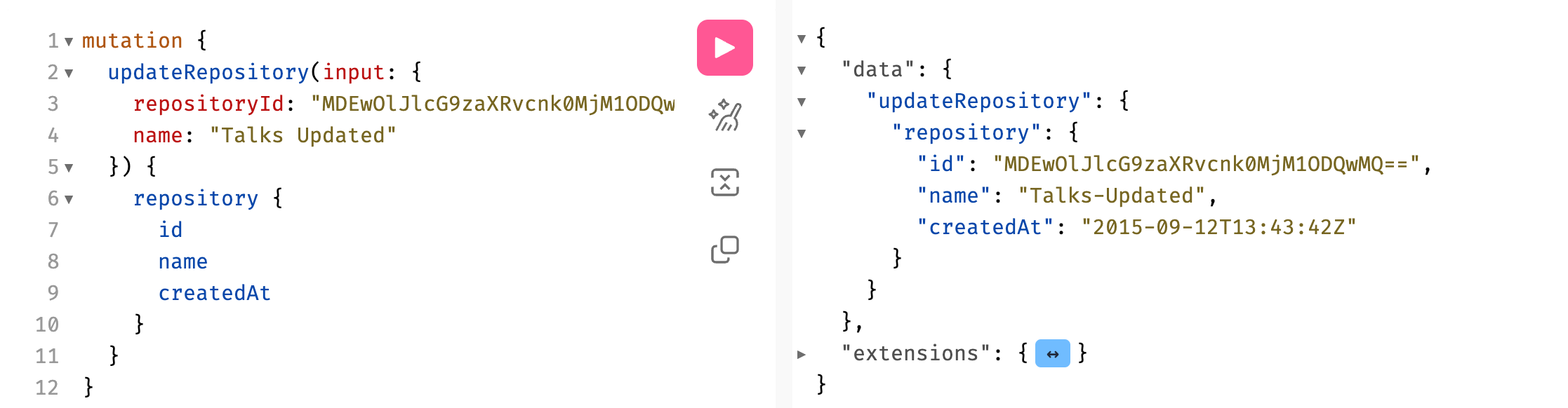
Schema Definition Language (SDL)
The Schema Definition Language (SDL) is the syntax used to write a GraphQL schema. It’s human-readable and used to define types, queries, mutations, and the relationships between types.
SDL is used to define objects, inputs, interfaces, unions, and enums, which are the building blocks of a GraphQL Schema.
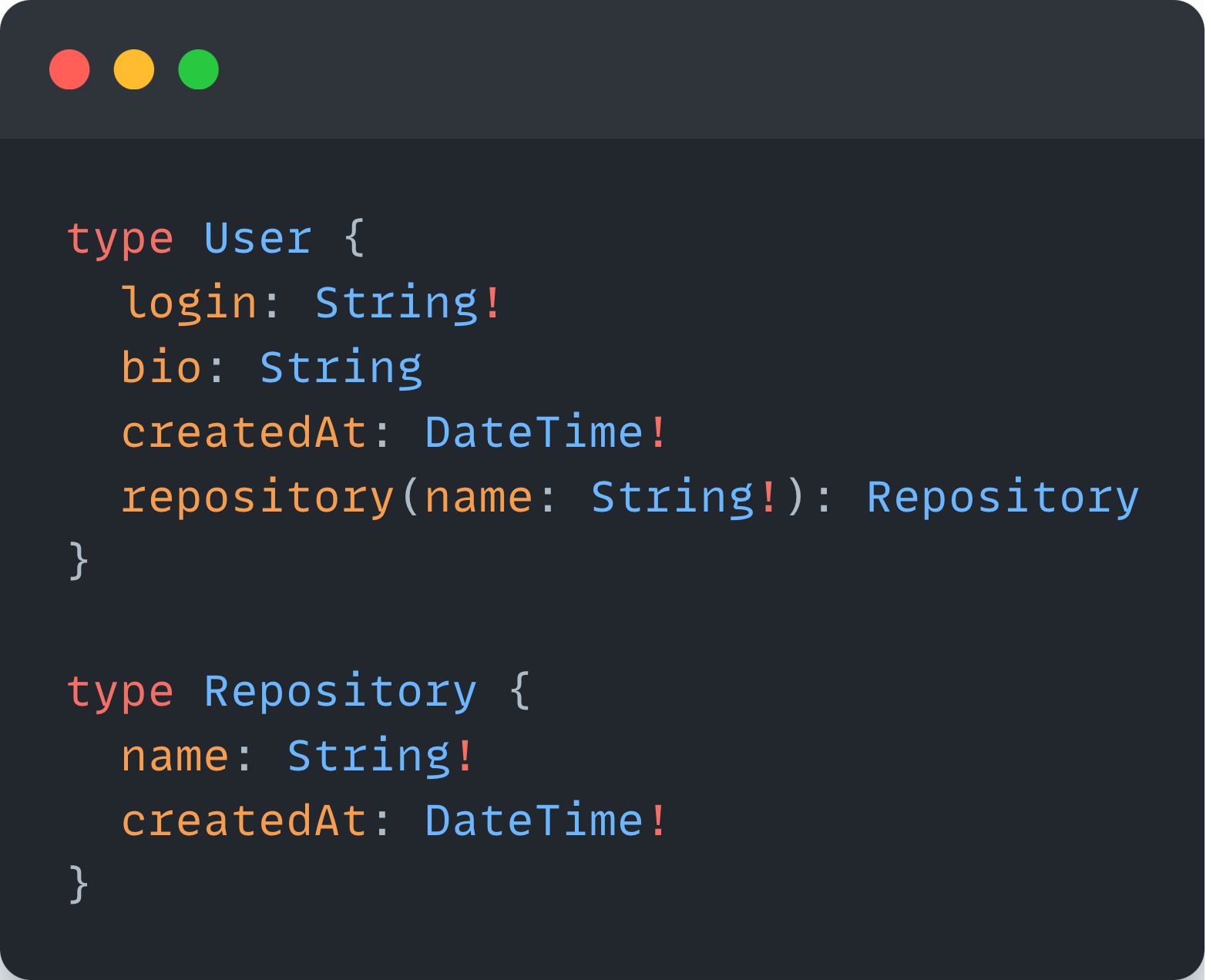
GraphQL Schema
The GraphQL Schema represents the contract between the client and the server. It defines the capabilities of the API by specifying how the client can fetch and mutate data.
The schema serves as a crucial blueprint that guides the structure of the queries and mutations. It informs the GraphQL Server of what functions to call when fetching or manipulating data and ensures that only valid operations are performed.
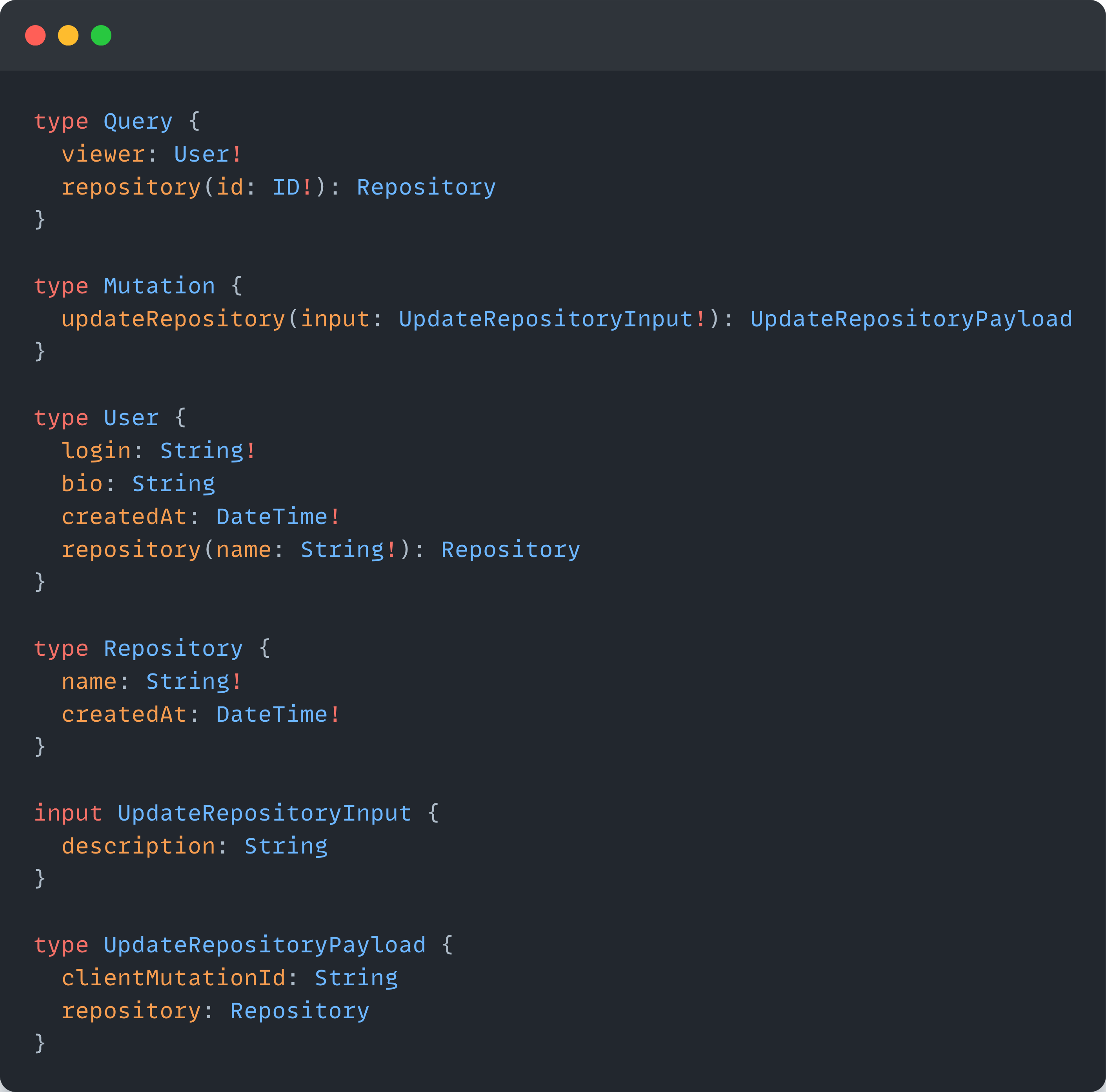
Resolvers
Resolvers are server-side functions that handle the fetching or manipulation of data for a particular field of a type in the schema. Each field on each type has a resolver function.
When a query or mutation is received, it’s the resolver’s job to produce the requested data and return it in the format the client requests.
As an example, let’s say we have the following defined query in our GraphQL Schema:

The corresponding resolver function may look something like this:
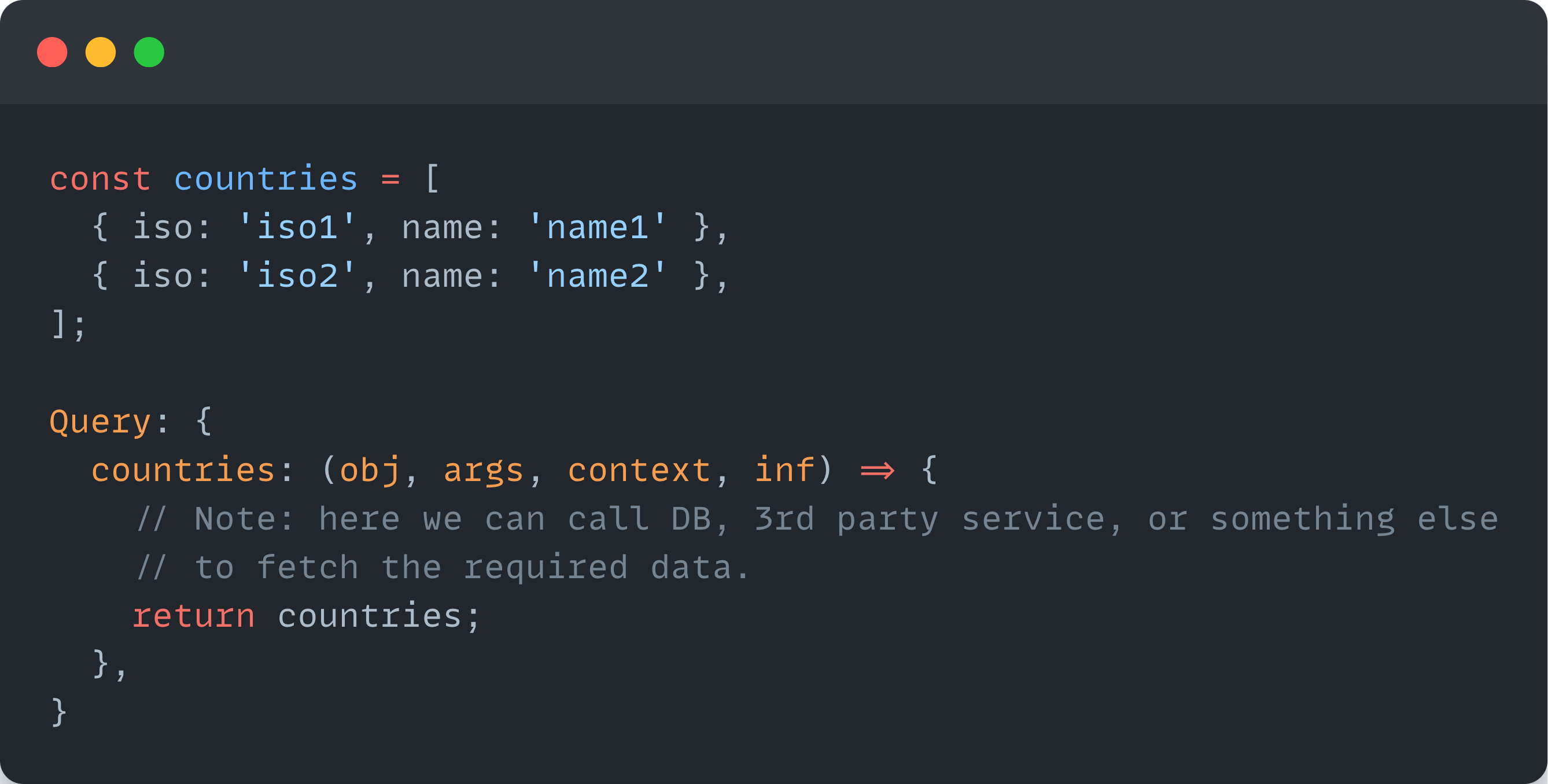
The GraphQL Server is responsible for calling the appropriate resolver functions depending on the user’s query and/or mutation.
Note: In the upcoming articles, I will write a more detailed step-by-step guide on implementing your own GraphQL Server where Resolvers’s usage will become clear.
High-Level Architectures
The next three architectures represent major use cases of GraphQL and demonstrate the flexibility in terms of the context where it can be used.
Simple
GraphQL Server with a connected database.
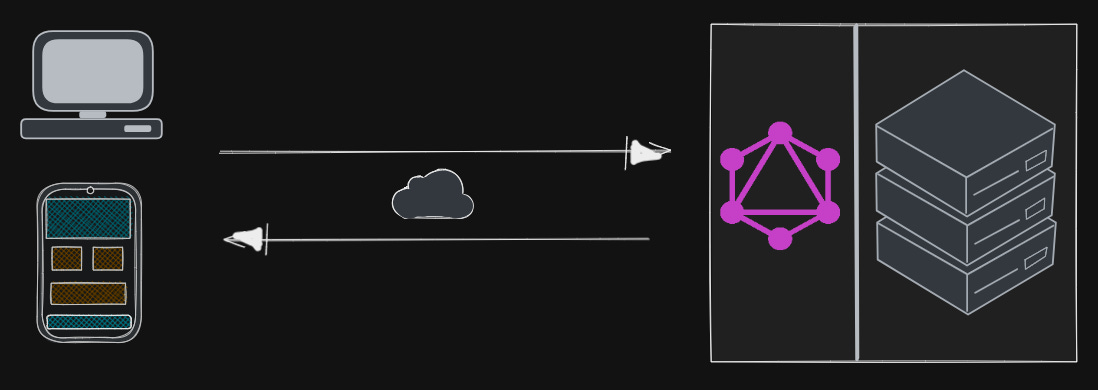
That’s a standard greenfield architecture with one GraphQL Server that connects to a single database.
Legacy Integration
GraphQL layer that integrates existing systems.
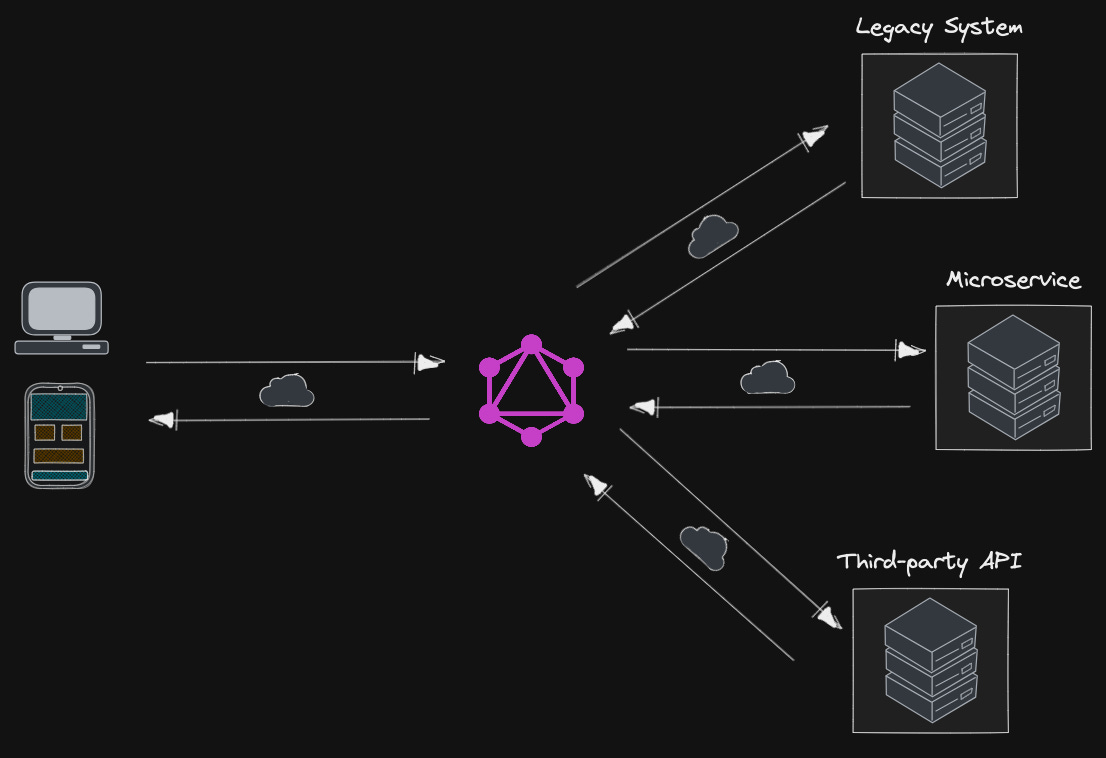
GraphQL allows you to hide the complexity of existing systems, such as microservices, legacy infrastructures, or third-party APIs behind a single GraphQL interface.
Hybrid
Hybrid approach with connected database and integration of existing system.

Both approaches can also be combined and the GraphQL Server can fetch data from a single database as well as from an existing system. This allows for complete flexibility and pushes all data management complexity to the server.
Conclusion
In the GraphQL Intro 101 series we covered the fundamentals of GraphQL from what GraphQL is, why, and how we use GraphQL to its Core Concepts and High-Level Architectures of use cases in which GraphQL is used.
It’s important to remember that:
GraphQL is only a specification.
This means that GraphQL is in fact not more than a long document that describes in detail the behavior of a GraphQL Server.
We haven’t seen any implementation details of GraphQL Server and other concepts like Subscriptions, Fragments, Directives, Federation, etc. I will cover them in upcoming articles since these are more advanced concepts and deserve separate articles.
Stay tuned for the upcoming articles of the GraphQL series where we will dig into implementing our own GraphQL Server with Apollo Server.
📚 Resources
https://graphql.org/learn/ - great docs
http://spec.graphql.org/ - the spec
https://www.howtographql.com/ - free and open source tutorial
https://foundation.graphql.org/ - the GraphQL foundation


After reading this eagerly Waiting for next article on the same topic.
Great write-up. In what scenarios do you think might GraphQL outperform REST in terms of performance, or when might REST be a better choice for performance-critical applications?