
3 Resilience Patterns That Keep a Backend Service Up When Its Dependencies Aren't
Timeout, retry with backoff, and circuit breaker — what each one actually does, and the order to stack them.
Here’s a failure that still bugs me.
A payment provider we used didn’t go down. That would’ve been easy. Instead, it got slow, 10 seconds per call instead of 200ms. No errors. Just slow.
Within a minute, our whole API was dead. Health checks, the stuff that never touched payments — everything timing out.
One slow dependency took down a service that
mostly had nothing to do with it. That’s cascading failure, and if you run anything in production long enough, you’ll meet it.
The fix isn’t “add a try/catch”. It’s three small patterns that bound the damage.
Let me show you what actually happened first, because once you see why it happens, the patterns are obvious.
Share this post & I’ll send you some rewards for the referrals.
Your AI shouldn’t grade its own homework (Partner)

Claude Code writes beautiful code. So does Codex.
But here’s the thing, they also think they write beautiful code.
And when you ask an AI to review code it just wrote, you get the intellectual equivalent of a student grading their own exam. Shockingly, they always pass.
CodeRabbit CLI plugs into Claude Code and Codex as an external reviewer, different AI Agent, different architecture, 40+ static analyzers and zero emotional attachment to the code it’s looking at. The agent writes, CodeRabbit reviews, and the agent fixes. Loop until clean.
You show up when there’s actually something worth approving.
One command. Autonomous generate-review-iterate cycles. The AI still does the work. It just doesn’t get to decide if the work is good anymore.
PS: Free tier available!
(Thanks to CodeRabbit for partnering on this post.)
Why one slow dependency takes you down
The thing that kills you isn’t the error. It’s the waiting.
Every request to that payment provider held something open while it waited: a connection from the pool, a worker, a slot. Normally a call returns in 200ms and the slot frees up right away. At 10 seconds, each slot is tied up 50× longer.
Your server has a finite number of those slots. They fill up. And once they’re all stuck waiting on the slow dependency, there’s nothing left to serve the requests that don’t even touch it. Your healthy endpoints go down because a different part of the system is locking all the resources.
So the real enemy is unbounded waiting.
Keep that in your head: every pattern below is really just a way to put a bound on something.
Timeout bounds how long any single call can wait.
Retry gives a flaky call a second chance, so a quick blip doesn’t become an error.
Circuit breaker bounds how much a dependency that’s actually down can keep hurting you.
Three bounds. That’s the whole idea.
Bound the wait → Timeout
Start here. If you only ever add one of these, make it this one.
A timeout says: this call gets X milliseconds, then I give up and move on. That’s it.
It’s the difference between “the payment service is slow, so this one request is slow” and “the payment service is slow, so my entire server is frozen”.
In Node, AbortController makes it clean:
async function withTimeout<T>(
fn: (signal: AbortSignal) => Promise<T>,
timeoutMs: number,
): Promise<T> {
const controller = new AbortController();
const timer = setTimeout(() => controller.abort(), timeoutMs);
try {
return await fn(controller.signal);
} finally {
clearTimeout(timer);
}
}
// fetch supports AbortSignal natively
await withTimeout(
(signal) => fetch("https://api.payments.com/charge", { method: "POST", signal }),
3000,
);One catch worth knowing: this only works if the thing you’re calling actually listens to the signal. fetch does. A lot of older clients don’t. So before you trust a timeout, check that the library honors AbortSignal. If it doesn’t, that’s your real bug, not the wrapper.
How long should the timeout be? Look at your dependency’s p99 latency in production and set it at 2–3× that. If p99 is 200ms, somewhere around 500ms–1s is sane.
Whatever you do, don’t leave it at the default. For a lot of clients, the default is “wait forever”, which is exactly what just killed us.
Recover from error blips → Retry (carefully)
Some failures are nothing. A dropped connection, a one-off 503, a node that restarted. Try again half a second later, and it just works.
So retry. But this is exactly where people make the outage worse instead of better.
Three rules keep you on the right side of that line.
1/ Add backoff and jitter. Don’t retry instantly, and don’t retry on a fixed schedule. If 100 requests fail at the same instant and all retry 200ms later, you’ve built a synchronized wave that slams the recovering service: the thundering herd.
The fix is to wait a bit longer after each failure (backoff) and add randomness so the retries spread out (jitter):
// "full jitter": wait a random amount up to the capped delay
const cap = Math.min(baseDelay * 2 ** attempt, maxDelay);
const wait = Math.random() * cap;That random up to cap is the part people get wrong. They compute a delay and then add random on top, so every retry still waits at least the full delay, and the herd never really breaks up. Random within the cap is what de-syncs everyone.
2/ Only retry what’s safe to retry. A retry is “do it again”. If the first attempt already charged the customer but the response got lost on the way back, doing it again charges them twice. Reads are safe. Writes are only safe if they’re idempotent: same call, same result, no matter how many times it runs. If an operation isn’t idempotent, give it an idempotency key or don’t retry it. (see How to Stop Charging Customers Twice)
3/ Don’t retry things that won’t get better. A 400 Bad Request means your input is wrong. Retrying sends the same wrong input again. Same for 401/403, auth doesn’t fix itself in 200ms. Retry network errors, timeouts, 429, and 503. Leave the 4xx alone.
The judgment, what to retry and how to space it, is the hard part, and that’s the part libraries can’t decide for you.
Bound the blast radius → Circuit breaker
Retry is great for an error blip. But what if the dependency is genuinely down, not for 200ms, for ten minutes?
Now retry is actively hurting you. Every call waits for its timeout, fails, waits for backoff, retries, fails again. You’re burning real resources to slowly rediscover something you already know: it’s down.
A circuit breaker fixes that, and the name is the whole metaphor. Like the breaker in your house: when something’s clearly wrong, it trips and cuts the current instead of letting the wires melt.
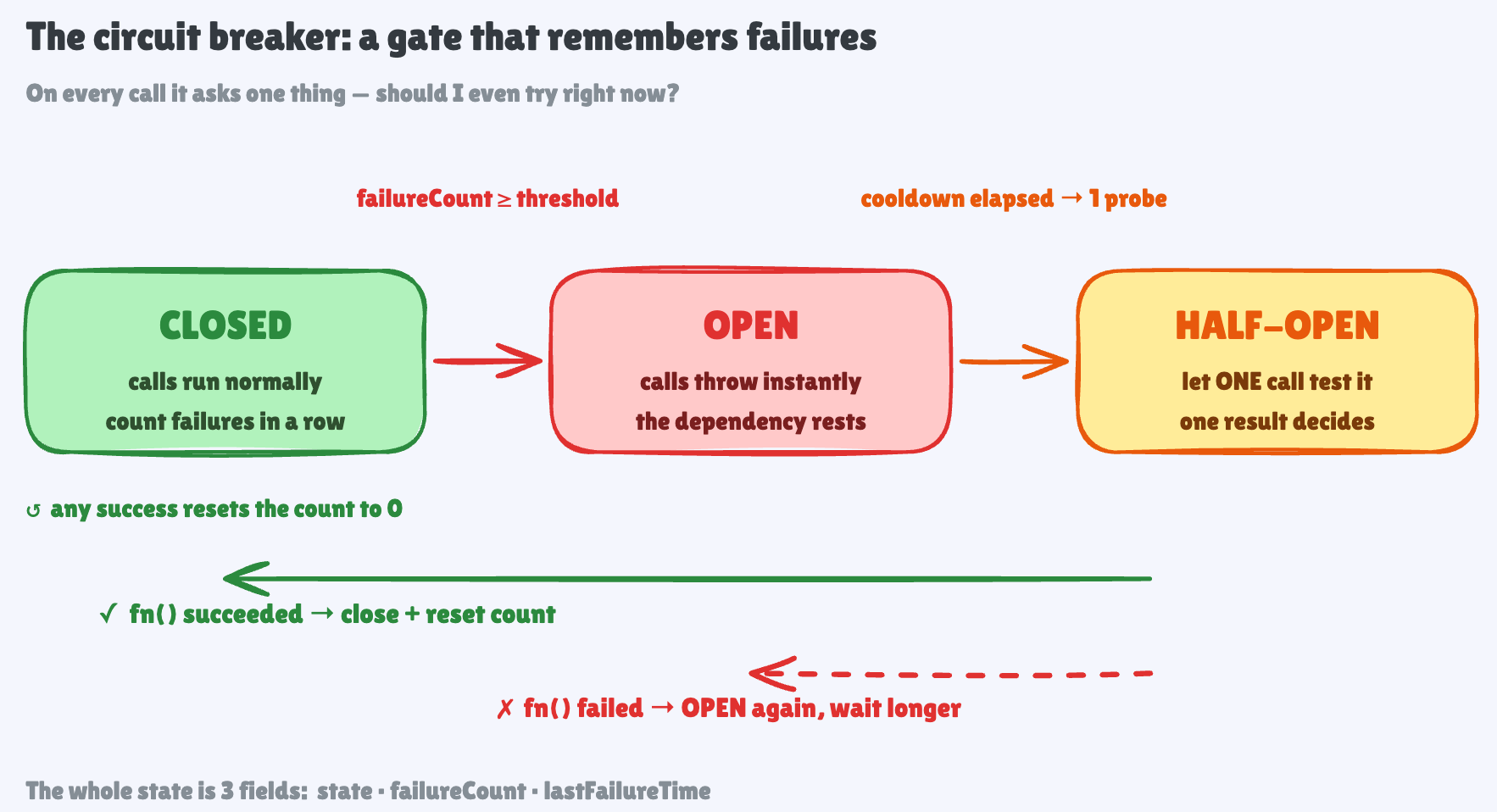
It has three states:
Closed — normal. Calls flow through. You count failures.
Open — tripped. Too many failures in a row, so you stop calling the dependency entirely. Fail instantly. No waiting, no wasted connections.
Half-open — testing the water. After a cooldown, let one call through. If it works, close the breaker and go back to normal. If it fails, open again and wait longer.
The payoff: when the payment service is down, your charge call fails in microseconds with a clear “payments are down right now” instead of hanging for three seconds and taking a connection slot down with it. Your other endpoints stay up.
Stacking them (the order matters)
These three aren't competing options. They're layers, and they wrap in a specific order:
circuit breaker → retry → timeout → the actual callRead it inside-out:
Timeout wraps each individual call, so no single attempt can hang.
Retry wraps the timeout, so an error blip, or a timed-out attempt, gets another shot.
Circuit breaker wraps the whole thing, so once it’s clearly down, you stop trying at all.
Note: watch the total budget. A 3-second timeout doesn’t mean the whole operation is bounded at 3 seconds. With three attempts plus backoff, the caller might wait ten.
There’s usually a real person on the other end of that wait, so bound the whole chain, not just each attempt.
Not everything needs all three
Reaching for all three on every call is its own kind of over-engineering.
Rough guide:
Call Timeout Retry Circuit breaker
Read query (SELECT) ✅ ✅ on transient errors ✅
Write to a payment API ✅ ✅ only with an idempotency key ✅
Email / notifications ✅ ✅ maybe
Internal microservice ✅ ✅ ✅
Cache (Redis) ✅ ❌ just fall back to the source ✅
Big file upload ✅ ❌ too expensive to redo ❌The one rule that’s not up for debate:
Timeout everything.
It’s the cheapest line of defense and the one that actually stops the cascade.
Retry and circuit breaker are refinements you add where they earn their keep.
Build it or grab a library?
For anything past the basics, two solid options:
cockatiel — retry, circuit breaker, timeout, bulkhead, fallback, all composable. The nice default.
opossum — a battle-tested circuit breaker with metrics hooks built in.
Roll your own when you want zero dependencies or full control. Reach for a library the moment you need bulkheads, metrics, or you catch yourself debugging your own half-open logic at 2am.
📌 TL;DR
One slow dependency can freeze a whole service, not by erroring, but by holding every connection hostage while it waits.
Timeout bounds the wait. Highest value, lowest effort — do this one even if you do nothing else. Just confirm your client respects
AbortSignal.Retry handles transient blips — but only with backoff + full jitter (random within the cap), only on errors that can get better (not 4xx), and only on idempotent operations.
Circuit breaker stops you from hammering a dependency that’s actually down. Let exactly one probe through on half-open, and don’t trip it on client errors.
Stack them circuit breaker → retry → timeout → call. Make sure retry treats a timeout as retryable, and bound the total time, not just each attempt.
Don’t add all three everywhere. Timeout always; the other two where they pay off.
Start with timeouts this week. Your on-call rotation will notice.

Follow me on LinkedIn | Twitter(X) | Threads
Thank you for supporting this newsletter.
Consider sharing this post with your friends and get rewards.
You are the best! 🙏

Press the Like button if you found this post helpful